

Reinforcement Machine Learning – Random vs Designed Choices
- Vathslya Yedidi
- June 8, 2020
Quick decision-making is tough as it is subject to several risks. Even though we know that our decisions have an irreversible impact, we often shy away from taking calculated risks and end up with random choices. Mostly, in my experience, it turns out to be a negative experience with respect to the immediate reward for my random action. Down the line, I really curse my bad luck as my experience is always negative, but never took a minute to really think what it takes to change my mindset to adopt a designed action rather than going with the luck factor. I believe many would have similar experiences and considered how to overcome that bottleneck with your thought process.
The insight behind Reinforcement Learning
I was determined to understand how a designed action or choices can yield a better result. Being an AI/ML practitioner, I came across the concept of reinforcement learning and learnt about the relevance of action, state and rewards for agents interacting with an environment. It was an insightful experience mapping the real world to the world of probability and statistics. I could realize the fact that a thoughtful approach while interacting with the real world could fetch far better results than making random choices. Quite often, I was ignoring to do that part of learning and ended up with the no brainers.
Now, this is not at all easy. ? You need to have a clear understanding of the reward policy with the environment you are dealing with. This happens only through your previous experience in similar situations. When you are left with multiple choices of action, you choose a specific action which could provide you with a better reward compared to the remaining choices. Now at this stage, you need to understand the different reward matrix for the choices you can make. This is possible, either by having a recorded history of all the choices against rewards or if you have an experienced mentor who can best guide you in taking the right choice with maximum rewards.
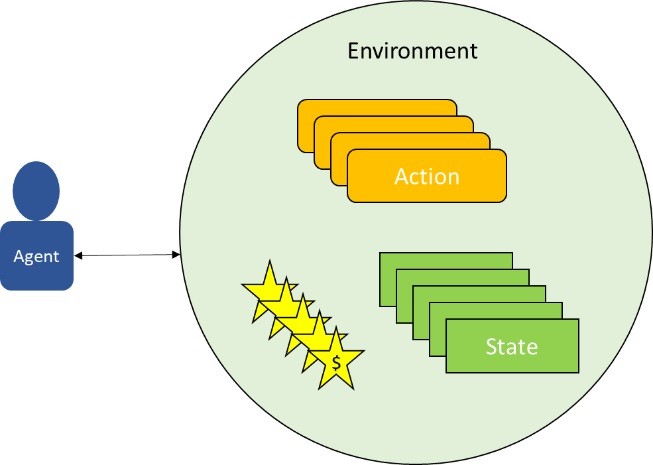
Figure 1 RL System
Here we have unveiled one of the important types of AI/ML concept called reinforcement learning (RL). Reinforcement learning is one of the key logic behind robotics, gaming and any other action- state transition use cases in the AI world. Here your experience is your historical data which guides you through the best or optimized path to reach your destination. The best or the optimum path is the one which takes you to your destination with a maximum positive rewarding experience.
Components for Reinforcement Machine Learning
When it comes to RL, we define certain key components which include Agent, Action, State, Reward, Policy, Episode and an Environment. An agent interacts with the environment through its action and transition from its current state to a future state receiving a reward following a policy. A policy is the collection of permissible actions defined for the agent to traverse across states. A policy becomes an optimal policy once it collects maximum rewards for all its actions transitioning across individual states. The challenge with RL is modelling the environment. When we say modelling the environment in the real world it is in fact related to the presence of a mentor who can guide us or provide insight/feedback about the reward or after effect/ impact of a certain action at a particular state. Most of the time, we don’t really depend on mentors as they are not available. These cases are referred to as model-less RL, where we interact with the environment and generate transition data for finding the optimal policy or path. In case of model-based problem, we in fact get the feedback from the model i.e. the mentor
Probability for random choices
Let us see how much difference it makes when you go with random choice compared to a designed choice. Consider this simple example where we are trying to answer a multiple-choice question and there are say 4 choices to select. In the case of random selection, the probability for each choice to be the right choice will be 25%. The probability of missing the correct choice is 75%, which is a really high chance to miss. Now in this scenario, if we could bring some experienced insights, then it definitely improves your probability of selecting the correct choice. Unfortunately, most of the time in this use case, we don’t have the option of getting a suggestion from a mentor or experienced person for guidance to select the right choice.
Let us see another example of you driving a car to a destination. You can have different routes to select from to reach the destination and you look for the best route to save time and money. Here you have two options to consider. Either you drive with the guidance of a mentor or go with your own past experience. Driving with the mentor means you can use google maps or any other route navigation app which helps you to select the optimized path based on the traffic condition in real-time. The second option will be to use your own experience to select the right choice of routes. The first one we shall refer to model-based RL and the second could be referred to as model-less RL.
Exploration Vs Exploitation
While dealing with real-world problems, getting a model-based solution often is very less and mostly we end up with model-less scenarios. In the case of model-less approach, the historical data or your past experience plays a major role is getting the right choice. If your past experience data is very limited, then the quality of your decision making gets limited gains. Hence, we expect a varied experience for better decision making. In RL terms, we need to generate more experience data with exploration rather than exploitation. In our driving use case with past experience, the driver will have a higher success rate in selecting the optimal route, provided the past experience data comes from an extensive exploration of different routes rather than just exploiting a very few selected routes.
So, on a personal front, if you want to make your choices accurate, you need to develop a mindset to explore first and then gradually move to the exploitation phase. Most of us only perform exploitation and end up leaving out the option of a better choice which is available.
Teach your Agent – Robo
Now we have seen that how an individual learns or trains himself to find the optimal choice based on the reward mechanism. The same principle is applied in training animals to perform tasks. A sniffer dog will be trained to perform a task in an optimal way by providing rewards based on the action taken. By constant training in this manner, the sniffer dog will explore all options and realize the optimal action which earns the maximum reward. Once the optimal actions are identified, the sniffer dog gives maximum probability to those optimal choices and keeps on exploiting it over time.
In RL, the same concept is applied to train an agent (Robot) to explore and find the optimal choices and then later allow to exploit the optimal choice with a maximum probability. The window for exploration is always kept open so that the agent will have a chance to find any other optimal choices which might come up in future.
Planning the reward
Another question which comes to my mind will be who suggests or recommends the reward. For a model-based system, the model could provide the reward value and for a model-less system, the rewards are learned through exploration. The environment should make a clear distinction with respect to the reward given to the agent for the action taken. In the absence of reward policy, the agent will not find it entertaining or useful to find an optimal choice. There should be strict penalty clauses for wrong choices for a faster learning process.
A sample play – Find your way
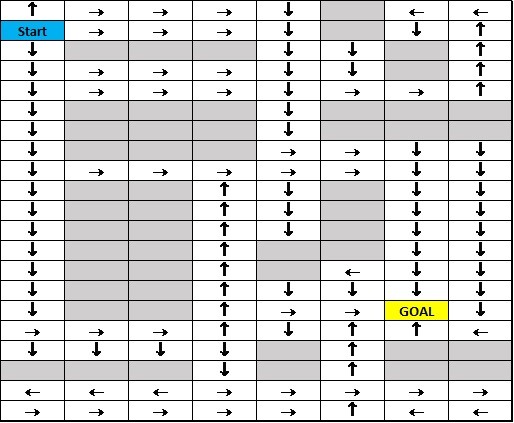
Figure 2: An RL Problem Statement
Let’s train an agent (Robo) to find a way to the “Goal” cell. Our agent is currently placed in the Start cell. Each cell here represents a “State” and agent can have 4 choices (UP, DOWN, LEFT, RIGHT) of action at each state, which lands it in a future state. We shall define the reward structure for each action and future state combination. To keep the sample easy to understand, let’s keep a negative reward of “1” for each step and for any block (grey cell) a negative reward of “10”. Reaching goal will fetch you a reward of “0”. To begin with the process, we initialize with a random policy to run through an episode. A policy is a specific list of actions for an episode which begins at the start state and ends in a terminal state. The terminal state could be the “GOAL” or any block or a dead end. The above figure depicts a few of the episodes and their policies. There could be many similar policies that our agent tasks will be iterating through episodes and find the optimal policy which gives the minimum negative reward reaching the GOAL state.
Playing with Episodes
There could be million plus possible policies for the problem statement given. We should be running a significant number of episodes till we see the delta in the rewards gains becomes significantly low compared to a set limit. To begin with, the agent initializes with a random policy and execute the first episode. Episode # 1 misses the Goal state and ends with a single state transition. The second time agent was lucky enough to run an episode which terminated at the “GOAL” state. Now if you calculate the total reward for the agent received after completing the episode will be -ve times the number of steps. For all Episodes, we calculate the rewards and finally compare which one has the lowest negative reward. The policy from the episode which returns the lowest negative reward and also ends in the “GOAL” terminal state is selected as the optimal policy for this particular problem statement.
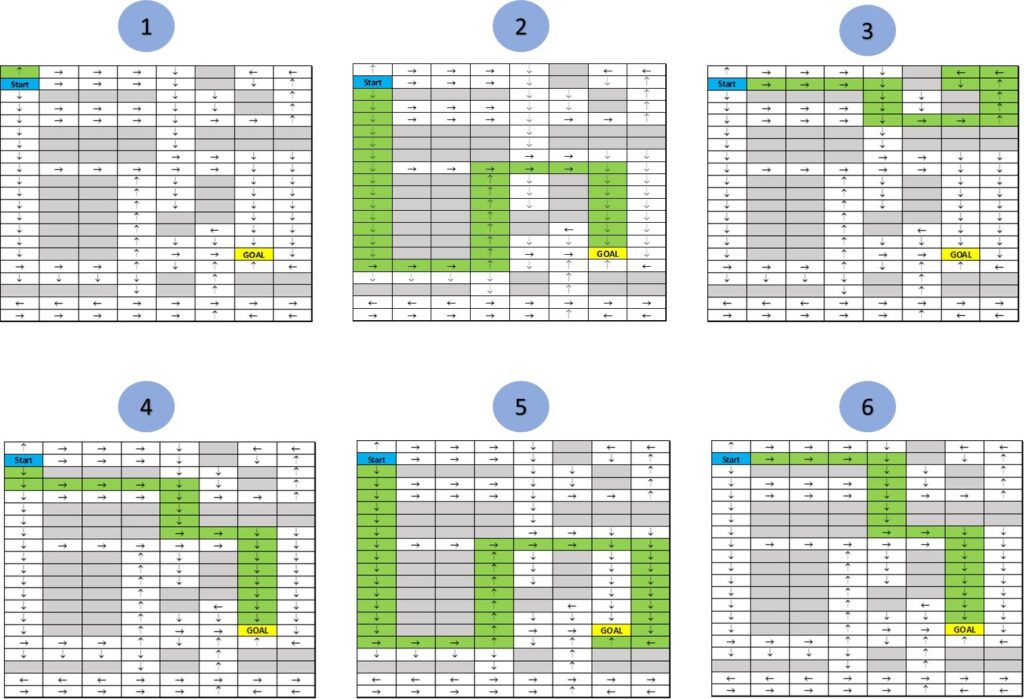
Figure 3: Episodes with different Policies
Going over the limited episode, we could figure out that we have two policies from Episodes 4 & 6 that have resulted in max rewards and reached the ‘Goal’ state. The Agent should further perform the exploration until all relevant paths are covered and then exploit the maximum reward policy as a solution to the problem statement.
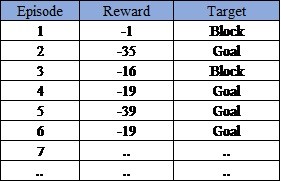
Figure 4: Rewards Data Sheet
Conclusion
The problem statement in the example shows that making a designed choice (reward-based) at each state can guarantee you a solution that takes you from your current state to the Goal state. Taking only random choices without any rewards mechanism won’t guarantee you a solution within a realistic time frame. The system has no practical means to converge to a solution unless a control mechanism is applied at every stage of decision making. This is the basis of all machine learning problems whether it is supervised, unsupervised or the Reinforcement learning types.
In this article, at a very high level, we discussed how we formulate an RL problem and run the episode to reach an optimal policy. This also gives us the importance of taking designed choices rather than just going away with random choices. Hope this will help in your starting journey towards designing agents that could solve your problems at the same time apply in your real life when choices need to be taken. All the best!