
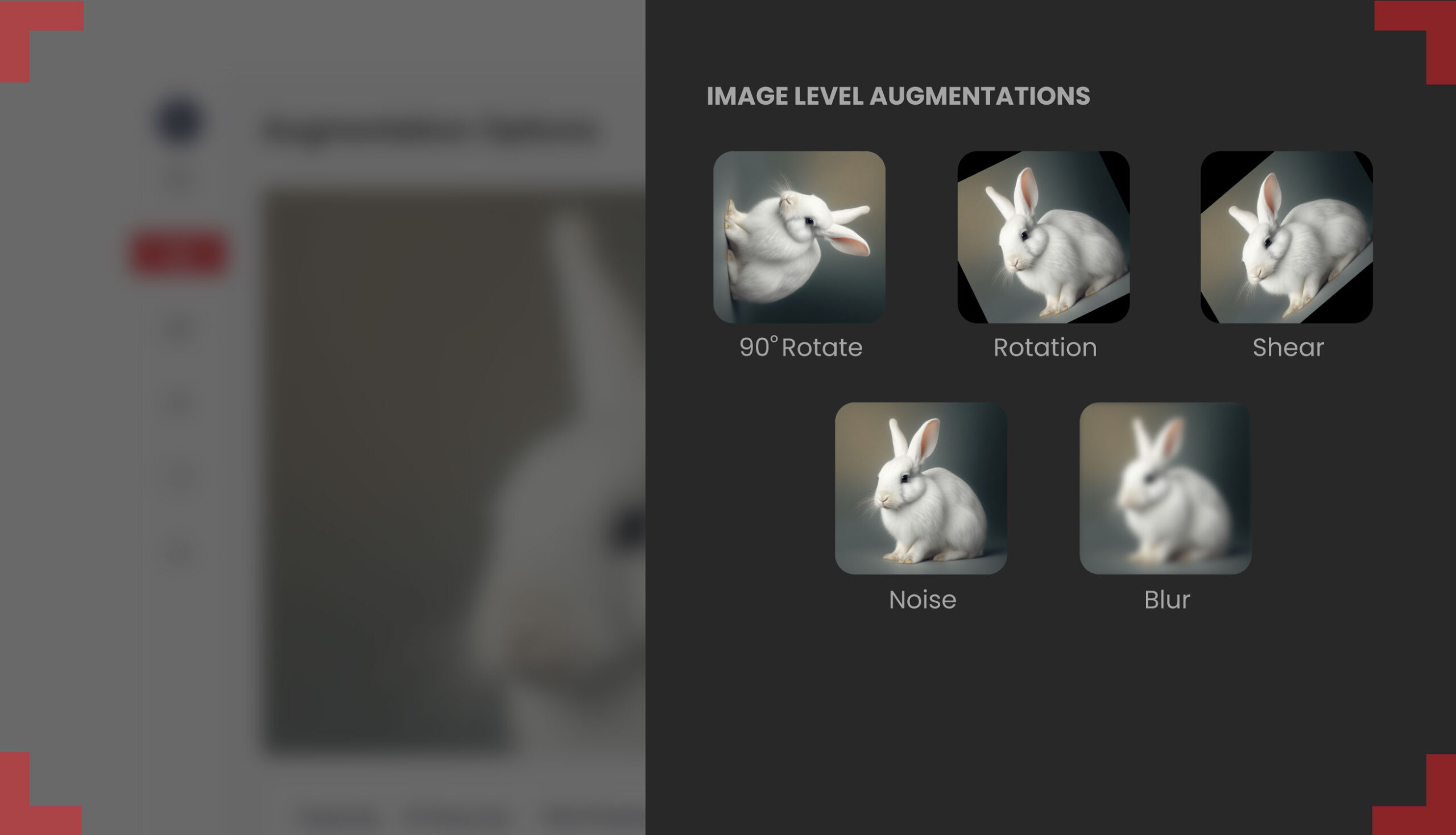
Image Data Augmentation: A Key Technique for Computer Vision
In Computer Vision, the quality and diversity of training data have a significant impact on the performance of Deep Learning models. However, gathering huge, high-quality datasets can be difficult and time-consuming, particularly in specialized industries or under certain conditions. Image Data Augmentation provides a more effective method for enriching and widening existing datasets, increasing the precision and applicability of Computer Vision models.
In this blog post, we’ll look into the Image Data Augmentation concept, including its importance, techniques, and best practices.
What is Image Data Augmentation?

Generating artificially new training data from preexisting image data is known as Image Data Augmentation. It involves modifying the original photos using a range of techniques, including flips, rotations, cuts, brightness fixes, and more. Thus, new, slightly altered versions of the original photographs are added to the training dataset, boosting the data’s variability and diversity.
Why is Data Augmentation Important for Computer Vision?
When working with limited or unbalanced datasets, Data Augmentation plays an important role in improving Computer Vision models to overcome their challenges. Implementing this method provides the following key advantages:
- Better Generalization: Data Augmentation is like giving the model more examples to learn from but in a smart way. It helps the model get used to different kinds of variations it might see in real life. This means the model can do a better job with new, unseen data, even if it’s a bit different from what it learned before. So, when the model faces real-world situations, which often differ from what it is trained on, it can still perform well because of this extra practice.
- Robustness to Variations: In everyday photos, there can be all sorts of differences like angles, lighting, and more. Data Augmentation is like giving the model a taste of all these variations during training. This way, the model does not get too fixated on specific examples and becomes more flexible. As a result, when handled with new photos featuring different angles or lighting, the model is well-prepared and capable of handling them effectively.
- Increased Sample Size: Collecting and annotating large datasets can be expensive and time-consuming. Data Augmentation offers a cost-effective solution by expanding the training data sample. This approach enables the development of more sophisticated and accurate models without the need for extensive manual data collection.
- Handling Class Imbalance: Certain datasets may have an unbalanced distribution of classes, with some classes being underrepresented compared to others. Data Augmentation can improve the model’s performance on minority classes by intentionally providing extra samples for underrepresented classes, hence contributing to dataset balance.
Different Data Augmentation Techniques to Boost Computer Vision Models
Data Augmentation for image classification contains a wide range of techniques, and the choice of transformations often depends on the specific task, domain, and characteristics of the dataset. Some of the commonly applied Data Augmentation techniques are:
1. Geometric Transformations

These include operations like rotation, flipping, scaling, cropping, and affine transformations, which introduce spatial variations and help models learn invariance to orientation, size, and positioning.
2. Color Space Adjustments

Data Augmentation Techniques like brightness adjustment, contrast enhancement, color jittering, and color space transformations (e.g., RGB to HSV) can simulate different lighting conditions, camera settings, and color distributions, improving model robustness.
3. Kernel Filters

Applying various kernel filters, such as Gaussian blur, sharpening, or edge detection, can simulate different image quality, focus, and sharpness levels, preparing models for real-world variations.
4. Random Erasing

This Image Data Augmentation method involves randomly removing or occluding portions of an image, forcing models to learn contextual cues and handle occlusions or missing information.
5. Mixing Images

Data Augmentation methods such as cutout, cutmix, and mixup combine multiple images or image regions, creating synthetic samples that may not exist in the original dataset. This can help models learn more complex visual patterns and improve their ability to handle challenging scenarios.
6. Adversarial Augmentation

By introducing small, imperceptible perturbations to the input images, adversarial augmentation can improve model robustness against adversarial attacks and improve generalization.
7. Domain-Specific Augmentations:

Depending on the application domain, specialized augmentation techniques can be employed. For example, in medical imaging, elastic deformations can simulate anatomical variations, while in satellite imagery, simulated atmospheric conditions or sensor noise can be introduced.
Best Practices and Key Considerations
Although Data Augmentation has several advantages, it’s crucial to use Image Data Augmentation techniques carefully and adhere to best practices to guarantee the greatest outcomes:
- Domain Knowledge and Relevance: The selection of augmentation approaches has to be predicated on both the particular task at hand and domain knowledge. Unrealistic or irrelevant transformations have the potential to add noise and worsen model performance.
- Maintaining a Balance Between Diversity and Realism: While introducing diversity is important, it’s also critical to keep things in check so that the augmented samples stay realistic and representative of the distribution of data found in the real world.
- Computational Overhead: A few Data Augmentation methods, such as adversarial augmentation or picture blending, can be computationally costly. The trade-off between computing resources and performance advantages must be taken into account.
- Augmentation Policies: Researchers and experts frequently use augmentation policies or automatic search approaches to find the best collection of transformations for a given job and dataset, as opposed to depending solely on a predetermined set of augmentations.
- Data Augmentation Pipelines: When integrating Data Augmentation into the training pipeline, it’s important to carefully analyze how preprocessing, augmentation order, and data loading will affect the efficacy of the augmentations and the performance of the model as a whole.
Conclusion
Image Data Augmentation has become an effective tool in the search for reliable and high-performing Computer Vision models. Data Augmentation tackles the issues of overfitting, lack of generalization, and lack of data by artificially growing and diversifying training datasets. Developers can customize their augmentation tactics to meet the specific needs of their applications by utilizing a variety of methodologies, such as geometric transformations and domain-specific augmentations.
Data Augmentation will play an even more crucial role as Computer Vision develops and tackles ever-more difficult problems. Organizations and researchers can maximize the capabilities of their Computer Vision models and guarantee dependable performance and adaptability in real-world scenarios by adopting this technique and adhering to best practices.
Interested to know more about Computer Vision solutions for your business? Let’s talk!