

Generative AI in Computer Vision: Transforming Industries and Shaping the Future
Improving Computer Vision models with diverse, high-quality datasets has always been a challenge. What if we say Generative AI is the solution for such problems? Using techniques like GANs (Generative Adversarial Networks) and VAEs (Variational Autoencoders) changes how we create and improve data. Generative AI in Computer Vision offers transformative possibilities across various fields. From enhancing Computer Vision products to creating immersive experiences in entertainment, Generative AI’s applications are vast and growing. This article explores the core aspects of Generative AI, its techniques, applications, and future directions, with examples to show its impact.
Understanding Generative AI
Generative AI refers to a type of Artificial Intelligence that can create new content, such as text, images, video, or audio. By learning patterns from training data, these models generate unique outputs with similar statistical properties. Techniques like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are commonly used to achieve these results.
Evolution of Generative AI
Generative AI has seen significant milestones over the years, each contributing to its advancement:
- 2010: Google’s autocomplete feature showcased AI’s potential in text prediction.
- 2014: Introduction of GANs by Ian Goodfellow, revolutionizing image and video generation.
- 2015: Amazon launched Alexa, a voice-activated AI assistant.
- 2019: OpenAI’s GPT-2 demonstrated advanced natural language processing capabilities.
- 2021: OpenAI released GPT-3.5, enhancing language generation significantly.
- 2023: OpenAI released GPT-4, a multimodal model which can handle different data prompts like images, text, document, etc.
Types of Generative AI
Image Generation Techniques
In the domain of image generation, GenAI uses techniques like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs).
Generative Adversarial Networks (GANs):
GANS are trained on several popular datasets such as MNIST, CIFAR, COCO, Imagenet, CelebA etc with many varied object classes. These datasets provide the raw material that GANs use to learn how to generate new images. By training on these diverse and extensive collections of images along with text prompts, GANs can learn to produce outputs that are not only realistic but also varied and detailed.
GANs consist of two neural networks that compete against each other —a generator and a discriminator—. Let’s take an example – “generator” is an artist, whose job is to create new pieces of art. The other is the “discriminator” artist, who acts like an art critic, judging whether the artwork is real or fake. The artist tries to create art that can fool the Critic, while the critic gets better at spotting fakes. Over time, this back-and-forth competition makes the artist’s artwork so good that it becomes hard to tell apart from real art. This is how GANs produce incredibly realistic images.

The above image is created using an open-source architecture called Stable Diffusion v1. It is a latent text-to-image diffusion model. To explore its integration with Python code and training custom stable diffuser model, refer to the GitHub link attached. https://github.com/CompVis/stable-diffusion
Variational Autoencoders (VAEs):
Variational Autoencoders (VAEs) are another powerful type of Generative model used for generating new data that resembles a given dataset. They are particularly good at tasks where understanding the underlying structure of the data is important.
VAEs have a unique architecture that enables them to learn and generate complex data distributions. This architecture consists of two major components: Encoders and Decoders. Let’s explore how this work together: Encoders work by encoding the input data (such as images) into a lower-dimensional space, capturing the essential features and Patterns of the data in a compact form. This lower-dimensional representation is called the latent space. The Decoders then decode latent space representation back into the original data space, generating new images that resemble the original ones.
For example – Think of VAEs as expert puzzle solvers. Imagine you have a collection of beautiful landscape photos. The VAE takes these photos and learns to break them down into puzzle pieces. It studies these pieces to understand the patterns, like colours and shapes, position. Then, it learns to put these pieces back together to recreate the original photo.
When asked to create a new photo, it uses its understanding of how these puzzle pieces fit together to generate a new, unique landscape that still looks realistic and like that the ones it has seen before.
So VAE’s strength lies in its ability to capture and recreate the essence of the data. This technique is widely used in applications such as Image Synthesis, Data Augmentation, and even creative tasks like art generation.
Popular Image Enhancement Techniques
Super-Resolution GANs (SRGANs) use a GAN architecture to upscale images, enhancing resolution and sharpness. The generator converts low-resolution inputs into high-resolution outputs, while the discriminator assesses their quality. Training involves optimizing perceptual loss, which includes content and adversarial loss, to improve image quality, resulting in high-resolution images from low-resolution inputs.
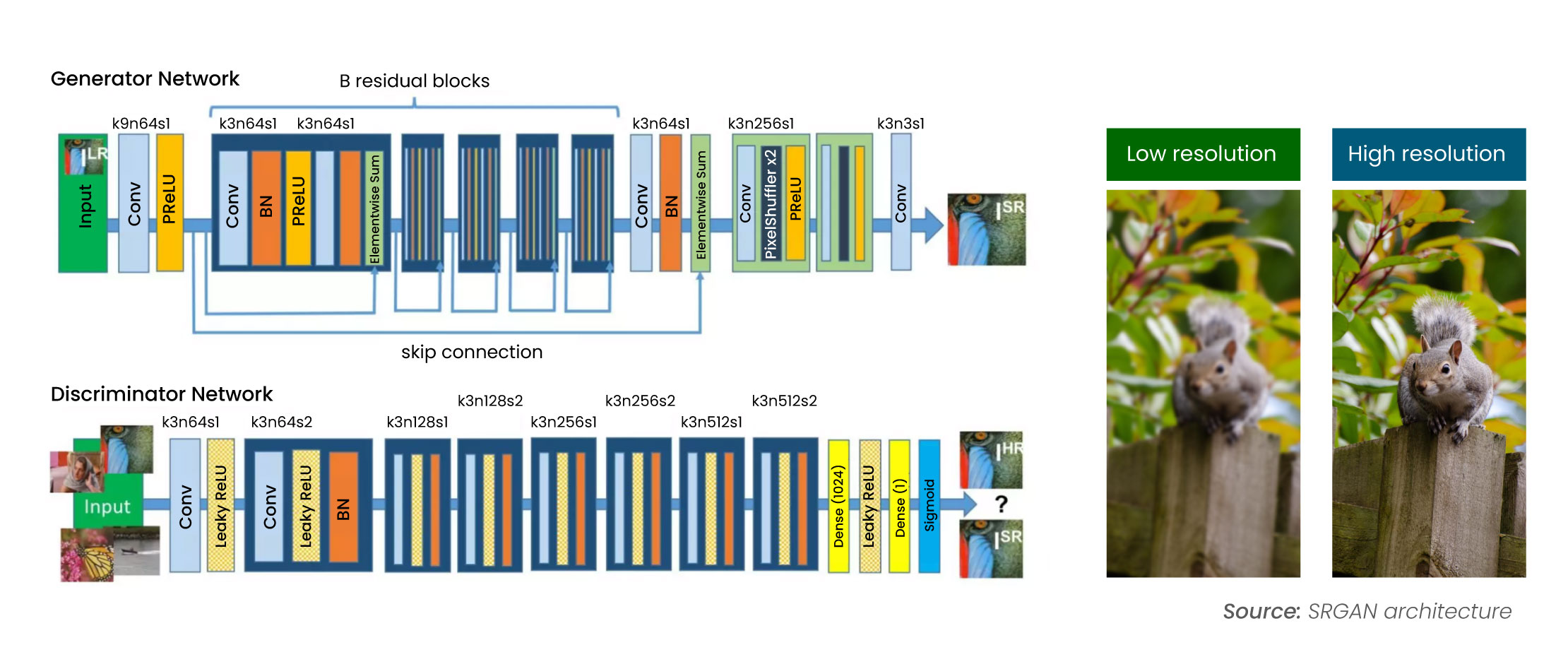
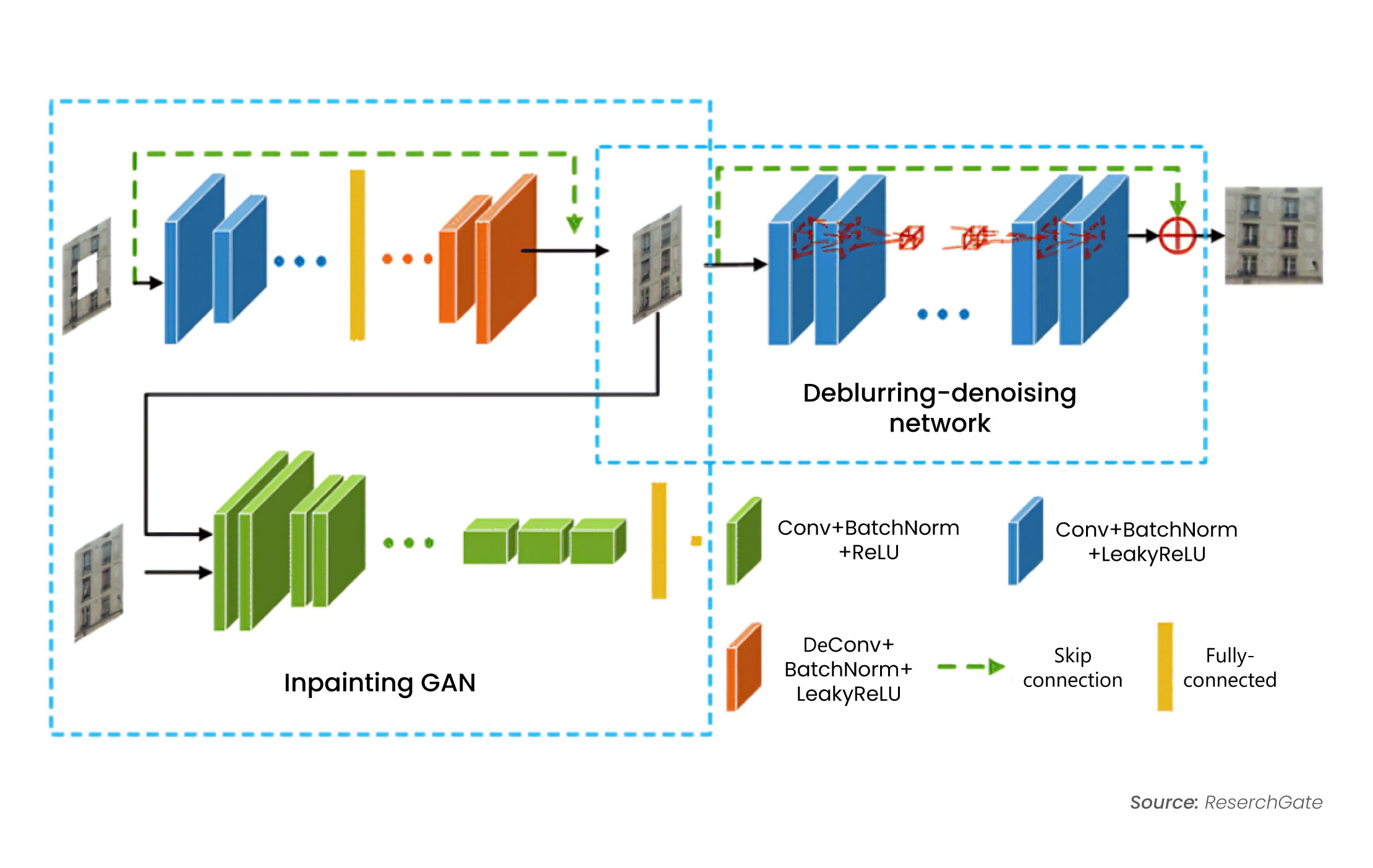
Image inpainting and restoration techniques aim to fill in missing parts of images or repair damaged areas. Techniques like contextual GANs and patch-based methods are used to comprehend the context and seamlessly fill in gaps or replace damaged sections with similar patches from the image. Deepfill v2 is one of the open-source frameworks designed for generative inpainting tasks.
Real-World Use case with Generative AI
Data Augmentation
Data Augmentation is crucial for enhancing the robustness of AI models. By applying transformations like rotations, translations, and colour adjustments to existing data, models can generalize better and achieve higher accuracy.
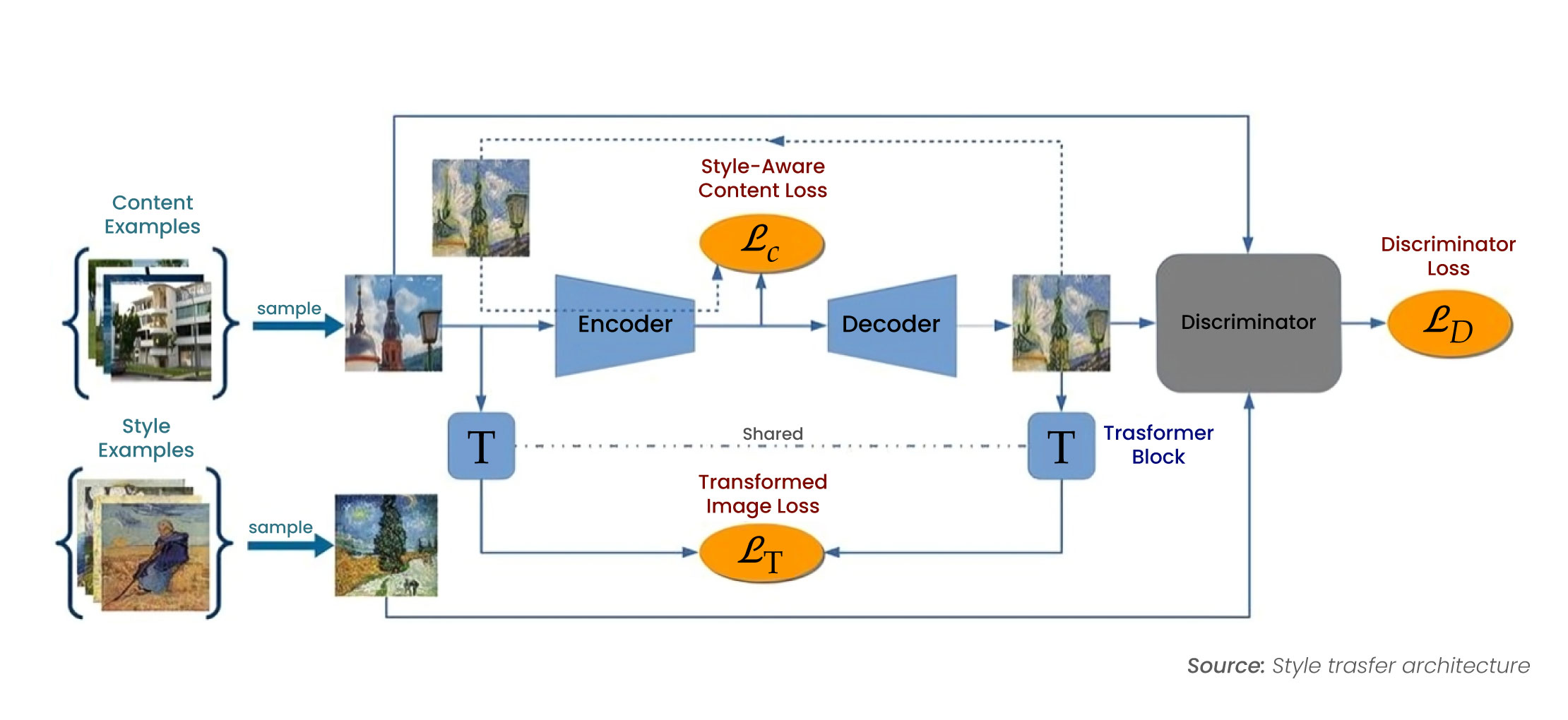
Style Transfer GANs
Style transfer GANs allow for creative edits to images by applying different styles while retaining essential features. This technique is used in various applications, from artistic creations to practical enhancements in model training.
Not only image data we can also augment –
- Text data (Transformers), Time-series data (RNN or LSTM), Audio data (WaveGAN or MelGAN), Tabular Data (Conditional Variational Autoencoders (CVAEs)) etc
Case – Study
Our Vision AI product, Vizinspect Pro is an advanced 360-degree inspection system for 5-gallon empty bottles, leveraging Computer Vision technology. Tasked with identifying defects like foreign particles and discoloration, we faced the challenge of limited historical defect data. We augmented our dataset using Generative Adversarial Networks (GANs) to generate diverse simulated defects based on customer input. Additionally, the tough production environment with dust, water droplets, and high humidity led to inaccuracies in our AI models. To combat this, we employed style transfer Cycle GAN to generate synthetic data mimicking these conditions, significantly enhancing our models’ accuracy and reliability.
Best Practices for Writing GenAI Prompts
A prompt is an input statement that guides a Gen AI model’s output. Gen AI models use prompts to generate new, original content statistically aligned with the context and requirements specified in the prompt.
While the specific details in a prompt reflect the type of desired output, best practices for writing text, image, audio, and video prompts rely on the same basic principles.
- Be Precise: Provide specific and detailed prompts to achieve more tailored responses.
- Provide Context: Include context to reduce ambiguity and help the model generate outputs that meet your intent.
- Avoid Leading Questions: Craft objective prompts free from leading information.
- Reframe and Iterate Prompts: If the initial response is not useful, rephrase the prompt or change the base multimedia sample and try again.
- Limit Response Length: Specify constraints, such as word or character counts for text or duration limits for audio outputs, to ensure concise responses.
- Experiment with Multiple Prompts: Break down questions or instructions into smaller prompts, or try different base images, audio clips, and video samples for better results.
- Review and Revise Outputs: Always review Generative AI outputs, as they will likely need editing before use. Be prepared to spend time on this crucial step.
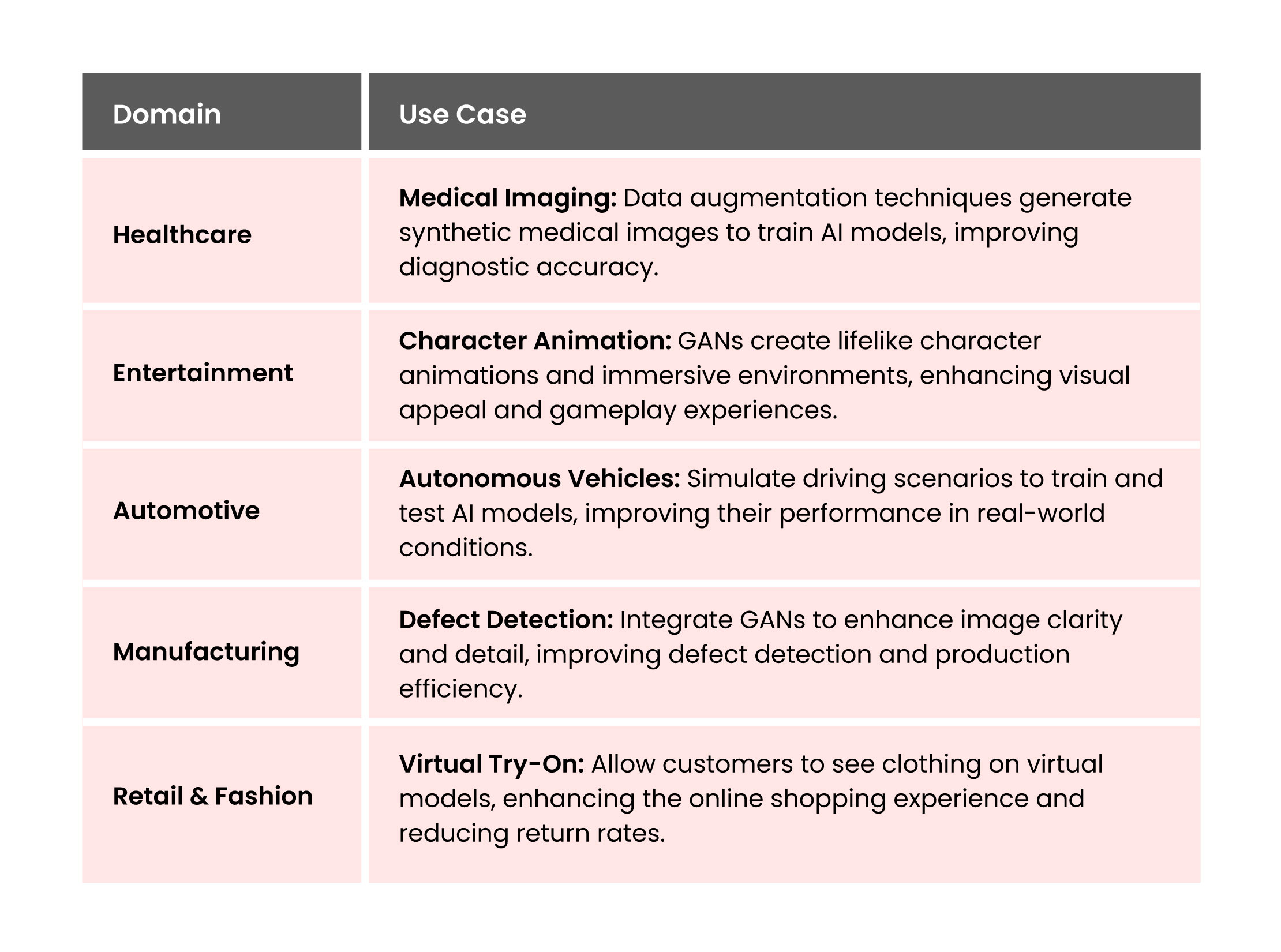
Applications of Generative AI
Generative AI has found applications in various industries, transforming processes and creating new opportunities. To understand its practical applications, let’s examine how different sectors can leverage this technology:
Future Directions of Generative AI
The future of Generative AI in Computer Vision holds exciting possibilities:
- 3D Scene Generation: Create realistic 3D scenes from 2D images or textual descriptions, enabling applications in virtual and augmented reality.
- Interactive and Adaptive Models: Develop models that generate content based on user input, allowing personalized and adaptive experiences.
- Neurosymbolic AI: Integrate symbolic reasoning with neural networks for more structured and interpretable models.
- Cross-Domain Image Translation: Transfer style, content, and attributes between different domains, facilitating tasks like image-to-image translation.
- Scientific Discovery: Use Generative models for breakthroughs in drug discovery, material design, and protein folding prediction.
- Energy-Efficient Architectures: Develop scalable architectures for Generative models, enabling deployment on resource-constrained devices.
- Ethical and Responsible AI: Focus on fairness, transparency, accountability, and societal impact to ensure Generative AI benefits humanity.
Conclusion
Generative AI is significantly advancing Computer Vision, providing robust capabilities for image creation, enhancement, and analysis. From healthcare to entertainment, its applications are propelling industries and opening new avenues for innovation.
As we continue to refine these technologies and address ethical considerations, Generative AI promises to drive significant advancements in AI-powered visual understanding and creation. The future of Computer Vision, augmented by Generative AI, holds massive potential for solving complex problems and enhancing human capabilities across various domains.
Connect with our experts to inquire more about our Computer Vision solutions and services.