

DINOv3 The Foundation Model Shaping the Future of Computer Vision
- Rahul Ravula
- October 14, 2025
Generate a quick summary
The evolution of Computer Vision in the past two years has marked a shift in priorities. For much of the last decade, progress was measured by incremental accuracy gains on benchmarks such as ImageNet, COCO, and ADE20K. While these benchmarks supported research progress, they offered limited value for real-world deployment. The current emphasis is on adaptability, efficiency, and cross-domain generalization, qualities essential for scaling Computer Vision systems into production.
Meta’s DINOv3 is positioned at the forefront of this shift. As the most advanced model in the DINO family of self-supervised vision architectures, it represents a significant step forward in self-supervised learning in Computer Vision. Through architectural innovations and advanced training strategies, DINOv3 establishes itself as a foundation model for visual intelligence. Its influence on Computer Vision can be compared to the transformation natural language processing experienced with the introduction of large-scale language models.
Training Without Labels Building a Billion-Image Foundation
Annotation has always been the slowest and most expensive step in building Computer Vision pipelines. In healthcare, agriculture, and manufacturing, labels are not just costly but inconsistent. Self-Supervised Learning (SSL) in Computer Vision changes this by allowing models to learn directly from raw images.
DNOv3 is trained on 1.7 billion curated images, distilled from a larger 17B-image collection. For training stability, the data mix also included ~10% batches from ImageNet. A 7-billion-parameter Vision Transformer architecture (ViT) teacher distills its knowledge into smaller student models such as ViT-Small, ViT-Base, ViT-Large, and ConvNeXt. Multiple student models are trained in parallel from a single teacher run, which significantly improves efficiency and ensures that pretrained backbones are available at different sizes for deployment for deployment of Vision Foundation Models.
Its standout innovation is Gram Anchoring, a regularization technique that prevents the collapse of dense feature extraction for segmentation and detection by preserving patch-level correlations throughout training. Alongside this, DINOv3 uses a composite training objective: a global DINO loss, iBOT-style patch prediction, and regularizers that encourage feature diversity. As a result, DINOv3 generates embeddings that remain reliable for both global tasks such as classification and retrieval, and pixel-level applications like segmentation and depth estimation.
Dense Representations for Pixel-Level Precision
Earlier foundation models delivered strong global understanding but faltered on dense tasks. DINOv3 changes this by ensuring that every spatial location in the feature map carries meaningful information.
The result is directly visible in production use cases:
- Manufacturers can detect micro-defects on fast-moving assembly lines.
- Clinicians can localize lesions with fewer annotated scans.
- Agricultural teams can monitor plant health at an individual scale.
- Analysts working with satellite imagery can preserve details without compromising context.
Combining global awareness with local fidelity, DINOv3 eliminates the long-standing compromise between context and precision. On standard dense benchmarks, it outperforms supervised pretraining baselines in segmentation, depth estimation, and object tracking.
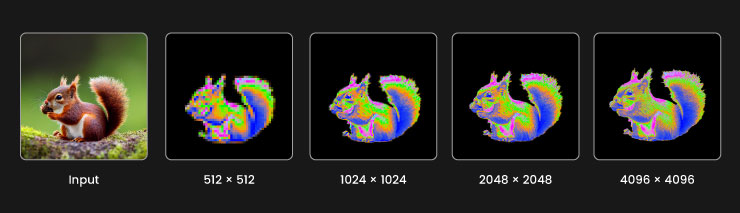
Engineering Stability for Massive Vision Models
Training Vision Transformers at massive image counts and parameter sizes has historically created instability, especially in dense tasks. DINOv3 addresses this challenge with three design choices:
- Gram Anchoring to stabilize dense features during long training runs
- High-resolution adaptation so representations remain valid even when inputs exceed training resolution.
- Axial Rotary Positional Embeddings with jitter, improving robustness across input dimensions and aspect ratios.
These methods together allow DINOv3 to sustain feature quality during large-scale training while expanding its usefulness to domains that rely on high-resolution input.
From Research to Deployment Practical Model Variants
Many research models remain impractical for deployment due to size and complexity. DINOv3 was designed to be different, with practical variants that enable the deployment of Vision Foundation Models across diverse systems. Its distilled variants give organizations flexibility in balancing accuracy and efficiency, and the models integrate easily through timm and Hugging Face Transformers. Pretrained weights are available openly, lowering the barrier for experimentation and adoption.
Many research models remain impractical for deployment due to size and complexity. DINOv3 was designed to be different. Its distilled variants give organizations flexibility in balancing accuracy and efficiency. Pretrained weights are openly available and integrate seamlessly through timm and Hugging Face Transformers, lowering the barrier for experimentation and adoption.
For deployment, DINOv3 brings three key advantages:
- Frozen backbones that deliver strong results without extensive fine-tuning.
- A plug-and-play design that can replace existing backbones in classification, detection, or segmentation pipelines.
- Hardware flexibility with support for GPUs, TPUs, and edge accelerators, along with pruning and quantization.
This makes DINOv3 equally practical for large-scale cloud inference and low-latency edge applications.
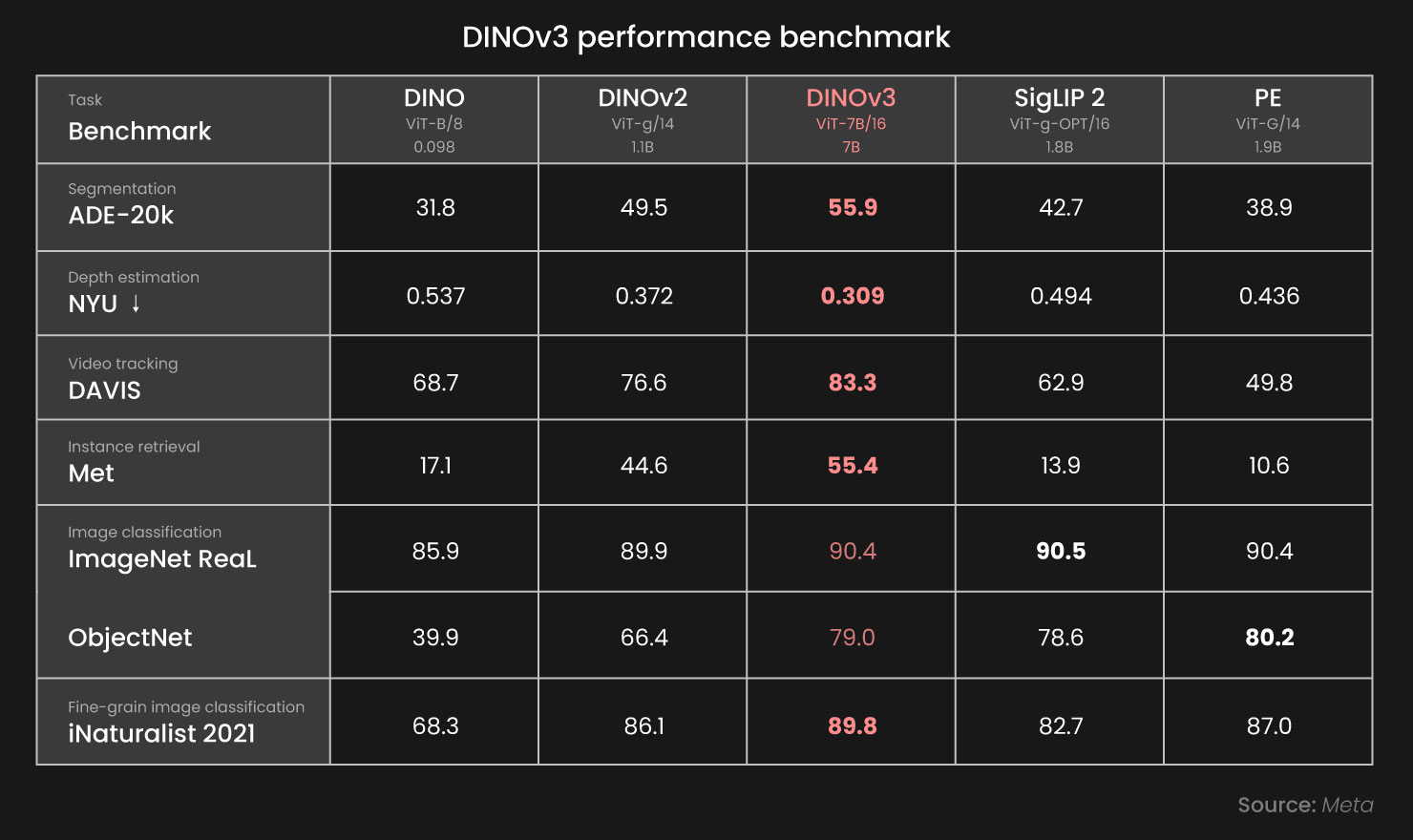
Cross-Domain Performance Across Industries
Adapting models to new domains has traditionally required retraining, making deployment costly and time-consuming. DINOv3 addresses this with representations that transfer effectively across tasks and environments. Even with frozen encoders, it delivers competitive or state-of-the-art results in classification, segmentation, depth estimation, and tracking.
Real-world use cases highlight this versatility:
- Healthcare: Efficient fine-tuning for histopathology and imaging tasks.
- Robotics: Frozen embeddings outperform supervised baselines in visuomotor control.
- Remote Sensing: Consistent performance across aerial and satellite imagery.
- Industrial Inspection: Stable defect detection under changing production conditions.
With this breadth of capability, a single DINOv3 backbone can replace multiple specialized models, reducing development overhead and simplifying deployment.
Shaping the Future of Computer Vision Systems
DINOv3 highlights a broader transformation across Computer Vision. The field is moving away from benchmark-driven progress and toward foundations built for deployment. Annotation-heavy workflows are being replaced by self-supervised training on massive image collections, while fragmented task-specific architectures are giving way to standardized backbones that support multiple applications.
For engineers, this means spending less time on bespoke training and more on building robust systems. For organizations, it lowers costs while extending the reach of vision AI into industries where development was previously impractical.
DINOv3 consolidates these advances into a foundation model that is both technically strong and deployment ready. With Gram Anchoring, high-resolution adaptation, efficient distillation, and support for zero-shot text alignment, it resolves long-standing challenges in self-supervised training and dense feature learning.
Its significance mirrors the shift seen in natural language processing: moving from task-specific models to universal backbones. The real challenge now lies not in building stronger pretraining pipelines, but in designing systems and applications that put them to work effectively.
Contact us to learn more about how Computer Vision can be applied to your business.