

Inside the Latest Computer Vision Models in 2025
- Vathslya Yedidi
- June 25, 2025
Advances in Computer Vision over the past year reflect a clear shift in priorities, from optimizing benchmark metrics to building adaptable, efficient, and deployable models under real-world constraints. Improvements in architectural design, such as structured attention and hybrid encoders, now align closely with requirements like label efficiency, latency tolerance, and domain generalization.
These latest developments in Computer Vision models influence production use cases: segmentation models requiring no class-specific training, detectors running in real-time on constrained hardware, and encoders transferring tasks with minimal adjustment. The emphasis has moved from isolated accuracy gains to architectural decisions that support long-term reliability and system-level integration.
This blog explores the key directions shaping the recent advances in Computer Vision models, from architectural evolution and self-supervised learning to efficiency, multi-task performance, and cross-domain adaptability. Let’s see what are the latest Computer Vision models in 2025.
Structured Attention in Modern Vision Architectures
Convolutional neural networks (CNNs) have long been the foundation of Computer Vision, but limitations in capturing long-range dependencies and global context have driven interest in attention-based architectures. Vision Transformers models (ViT) introduced a new way to process images, treating them as sequences rather than fixed grids, and enabled more generalized visual reasoning.
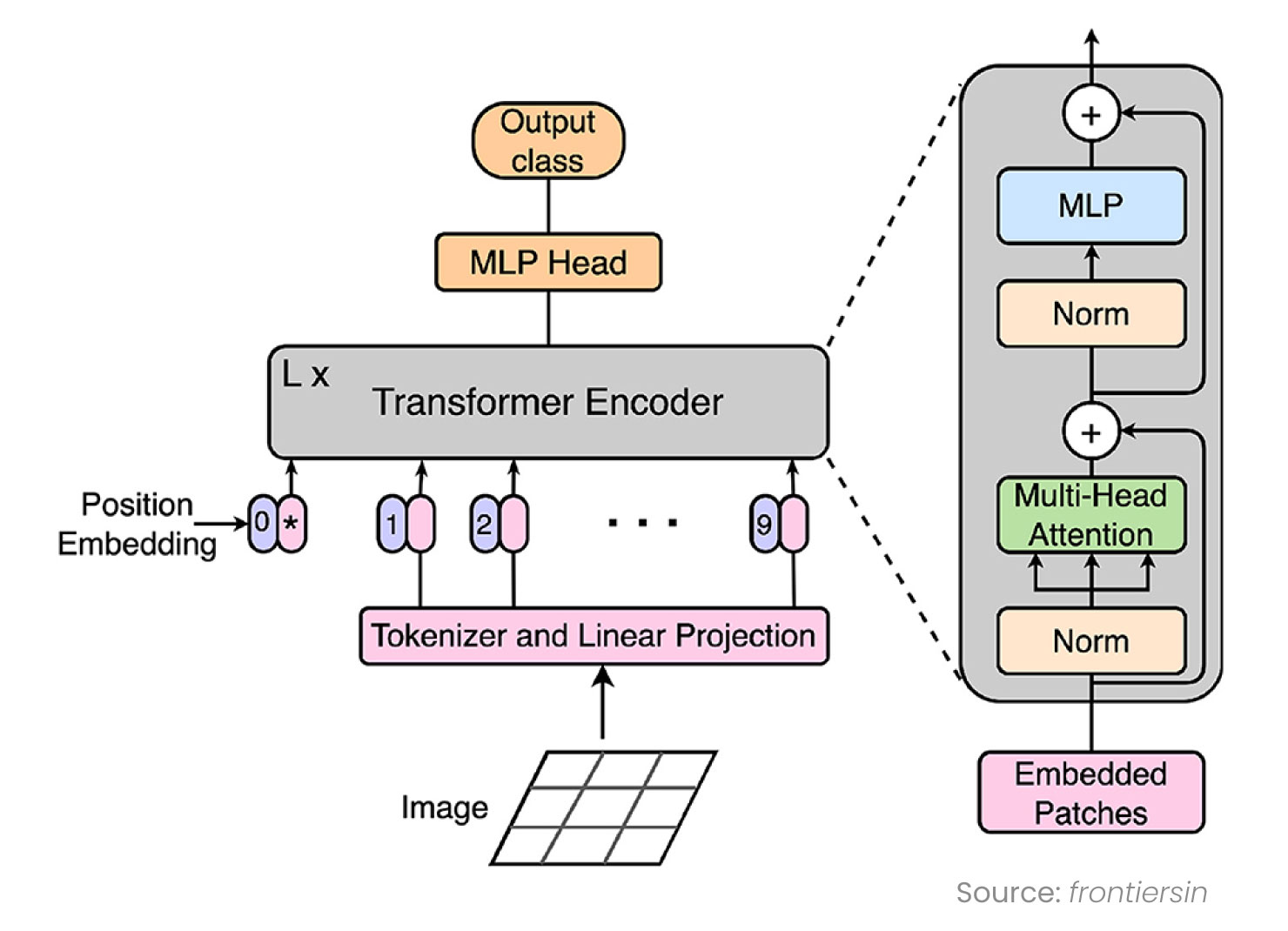
Fig: Attention Mechanism in ViT
Since then, newer models have evolved this approach:
- Swin Transformer: Introduced shifted window attention to efficiently capture local and global image features with reduced computation.
- MaxViT: Combined grid and winxxASXdow attention for improved spatial understanding without high computational cost.
- FeatUp: Incorporated attention into feature upsampling, addressing a common bottleneck in segmentation-heavy tasks.
These models depart from purely local receptive fields and enable better semantic integration for dense prediction tasks like keypoint detection, panoptic segmentation, and visual scene understanding.
Unified Models and Task Transferability
One of the most impactful 2025 trends in Computer Vision models is the development of task-agnostic architectures. Rather than training separate models for classification, segmentation, and detection, recent designs aim to support multiple vision tasks from a single, pre-trained backbone.
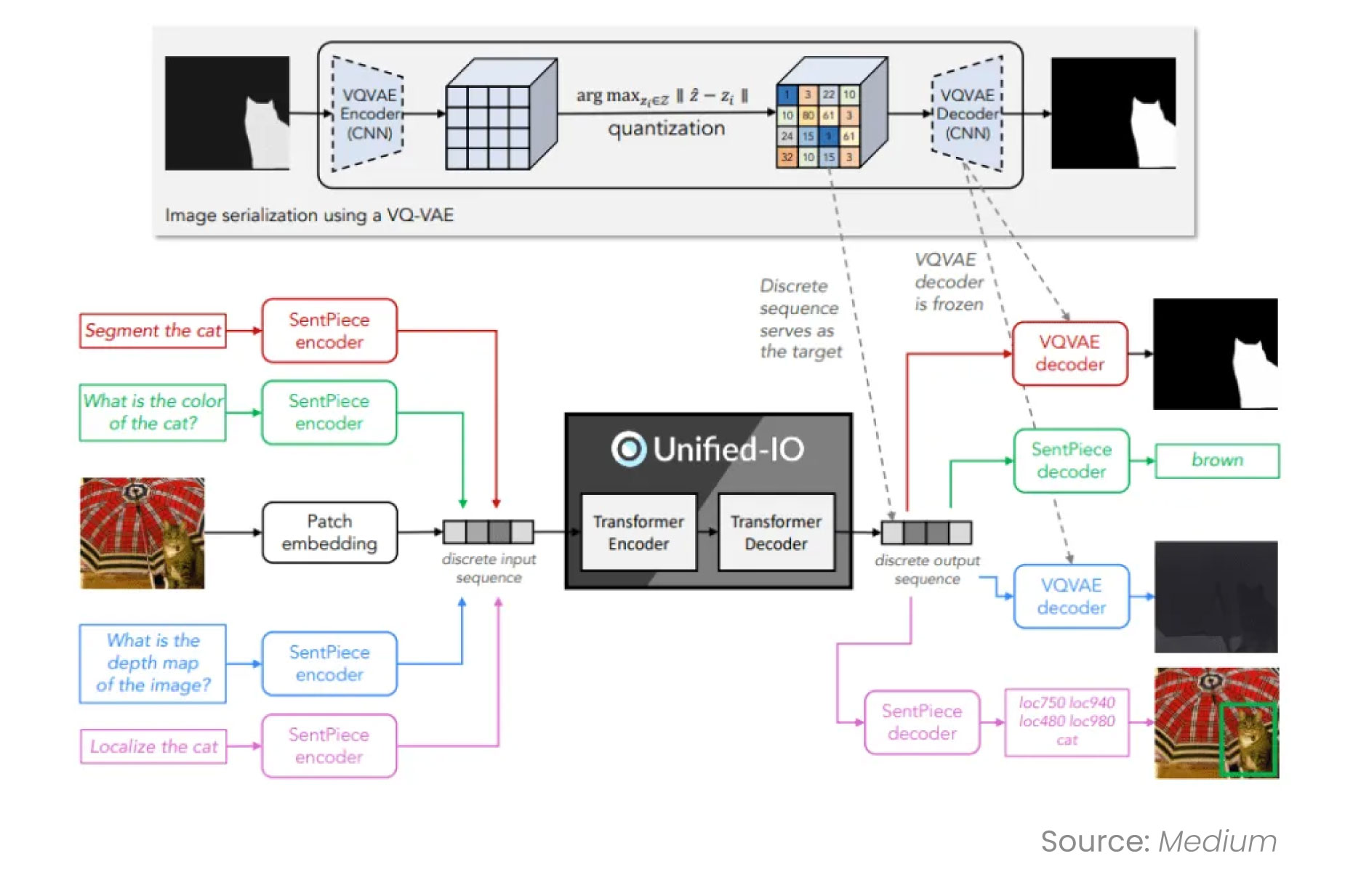
Fig: Unified model in Computer Vision Tasks
Models such as:
- DINOv2 (Meta): A self-supervised vision encoder trained on a massive image corpus, with downstream adaptability to a wide range of tasks.
- Segment Anything Model (SAM): Trained to perform segmentation based on prompts, allowing flexible use without retraining for specific classes.
- OpenCLIP: A vision-language model extending CLIP to broader domains, enabling multi-modal applications such as cross-modal retrieval and visual search.
These models shift the focus from hand-engineering separate pipelines to building shared infrastructure, simplifying model governance and accelerating deployment across varied visual workflows.
Inference Efficiency and Edge Readiness
Inference efficiency is critical for real-world applications. Many environments, such as industrial facilities, logistics hubs, or embedded systems, demand low-latency processing on constrained hardware. While early transformer models struggled with deployment overhead, new iterations emphasize performance without excessive computational load.
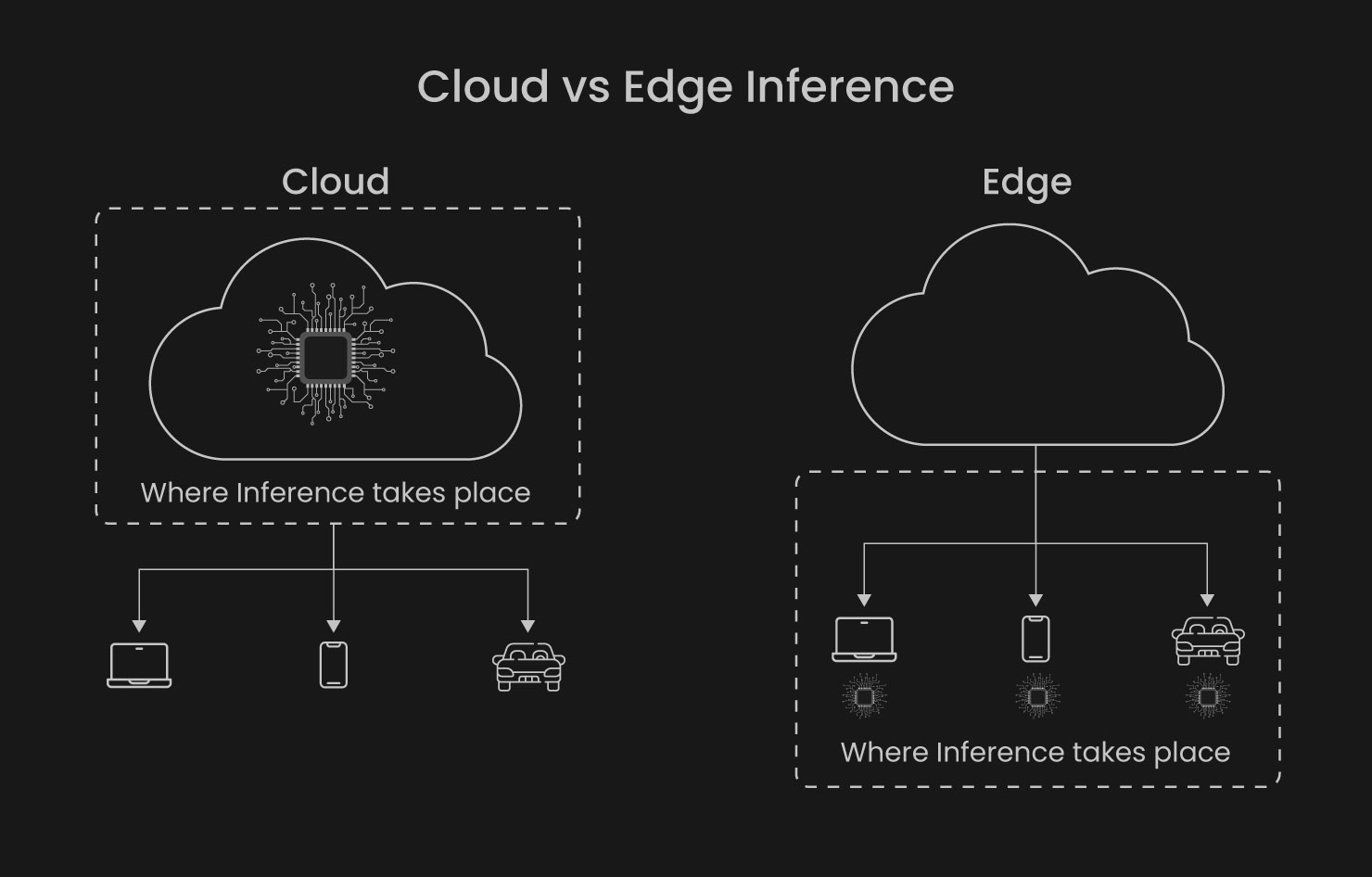
Fig. Cloud Vs Edge Inference
Notable examples:
- YOLOv11: The latest in the YOLO series, offering improved real-time detection accuracy, lower latency, and better deployment efficiency across edge platforms.
- RT-DETR: A real-time Detection Transformers version designed for high throughput in live object detection pipelines.
- MobileSAM: Brings the capabilities of the Segment Anything architecture to mobile and edge environments.
These models deliver precise vision capabilities while maintaining inference times well below 100 ms, a requirement for high-speed inspection lines or real-time robotics.
Self-Supervised Learning and Label-Efficient Training
Traditional vision systems have been dependent on large volumes of labeled data. Labeling data at scale in many domains, such as medical imaging, manufacturing, and defense, is either cost-prohibitive or practically infeasible.
Recent models rely on self-supervised learning (SSL) to overcome this challenge. Instead of relying on manual labels, SSL trains models to predict masked regions, contrast image views, or reconstruct corrupted inputs.
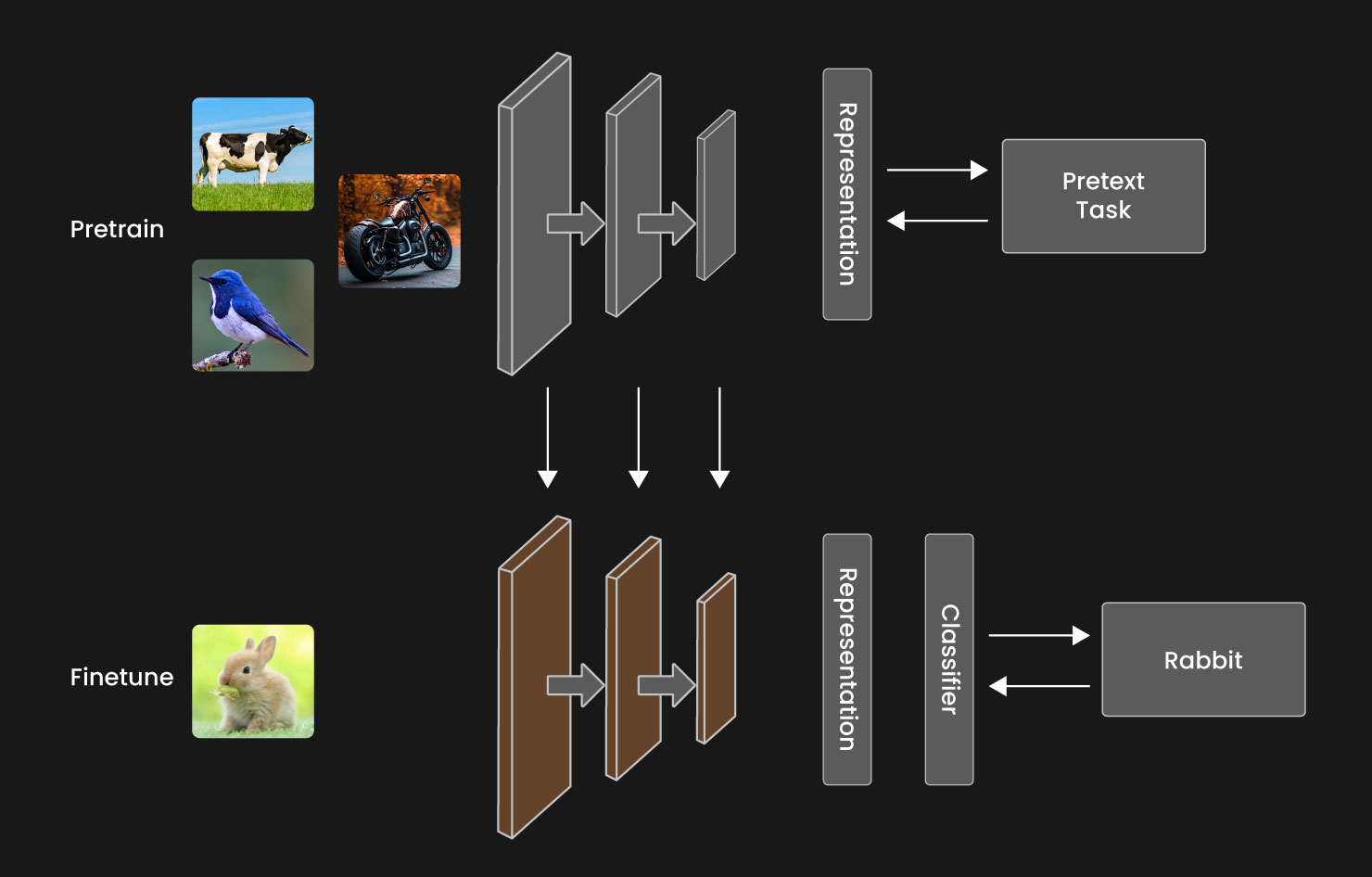
Fig: self-supervised learning
Prominent approaches include:
- Masked Autoencoders (MAE): Teach models to reconstruct images from partial input, enhancing robustness and generalization.
- MoCo v3, SimCLR, and DINO: Contrastive learning techniques that build semantic understanding from raw data.
These models learn generalized visual features that transfer across tasks and domains, significantly reducing the reliance on expensive annotation pipelines.
Vision-Language Integration and Multi-Modal Learning
Modern Computer Vision models are designed to operate alongside textual inputs, enabling multimodal reasoning beyond traditional perception tasks.
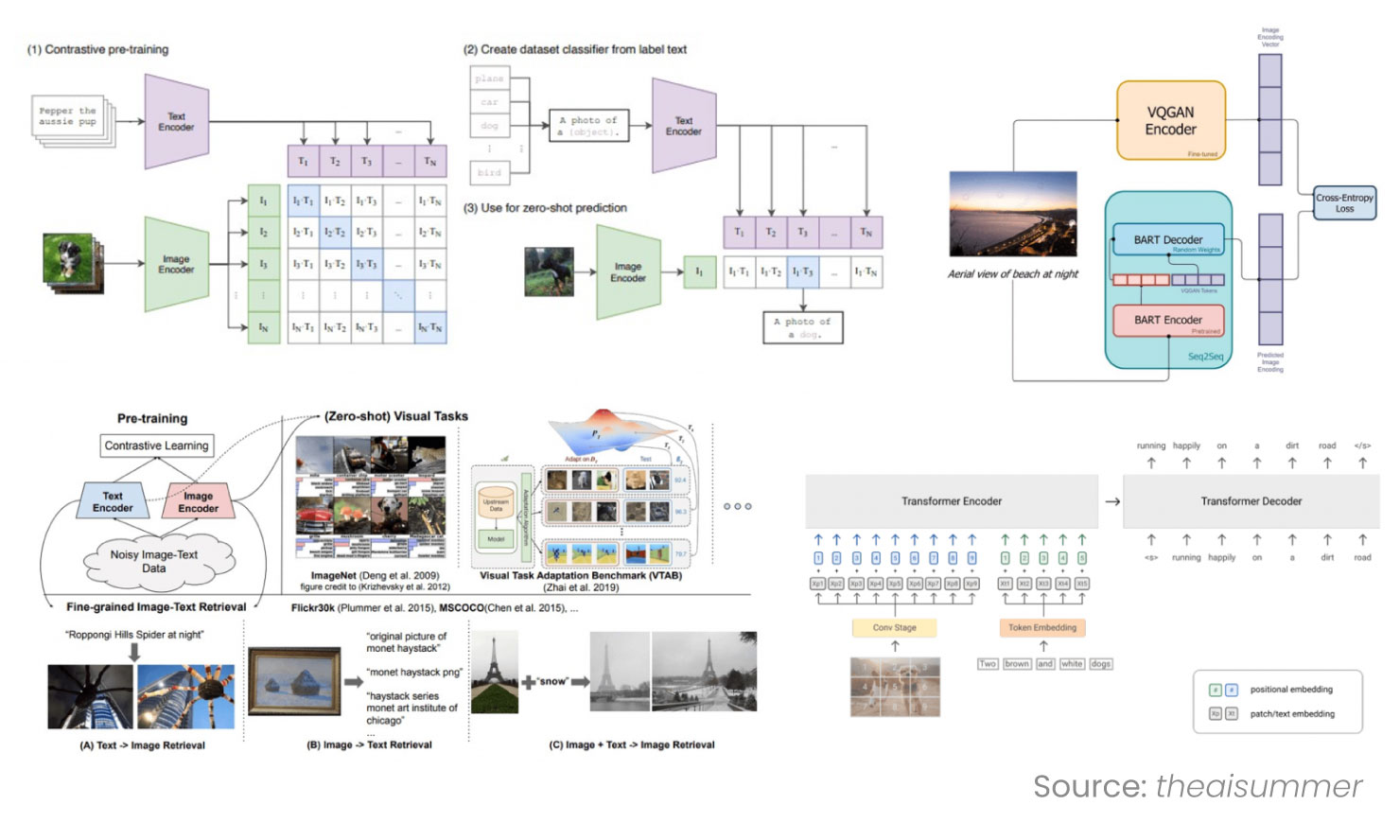
Fig: Vision-Language Integration
Models like:
- CLIP: Aligns images and text in a shared embedding space, allowing for natural-language classification, filtering, and search.
- BLIP-2 and GIT: Enable generation and interpretation of text from images, powering applications like visual question answering or scene captioning.
- Flamingo and PaLI: Integrate vision and language at scale, allowing fluid interaction between different data modalities.
Unlocks applications where visual context must be interpreted alongside verbal input, such as exception reporting in supply chains, regulatory compliance in pharmaceuticals, or retail analytics powered by descriptive tags rather than fixed classes.
Deployment Ecosystems and Model Operationalization
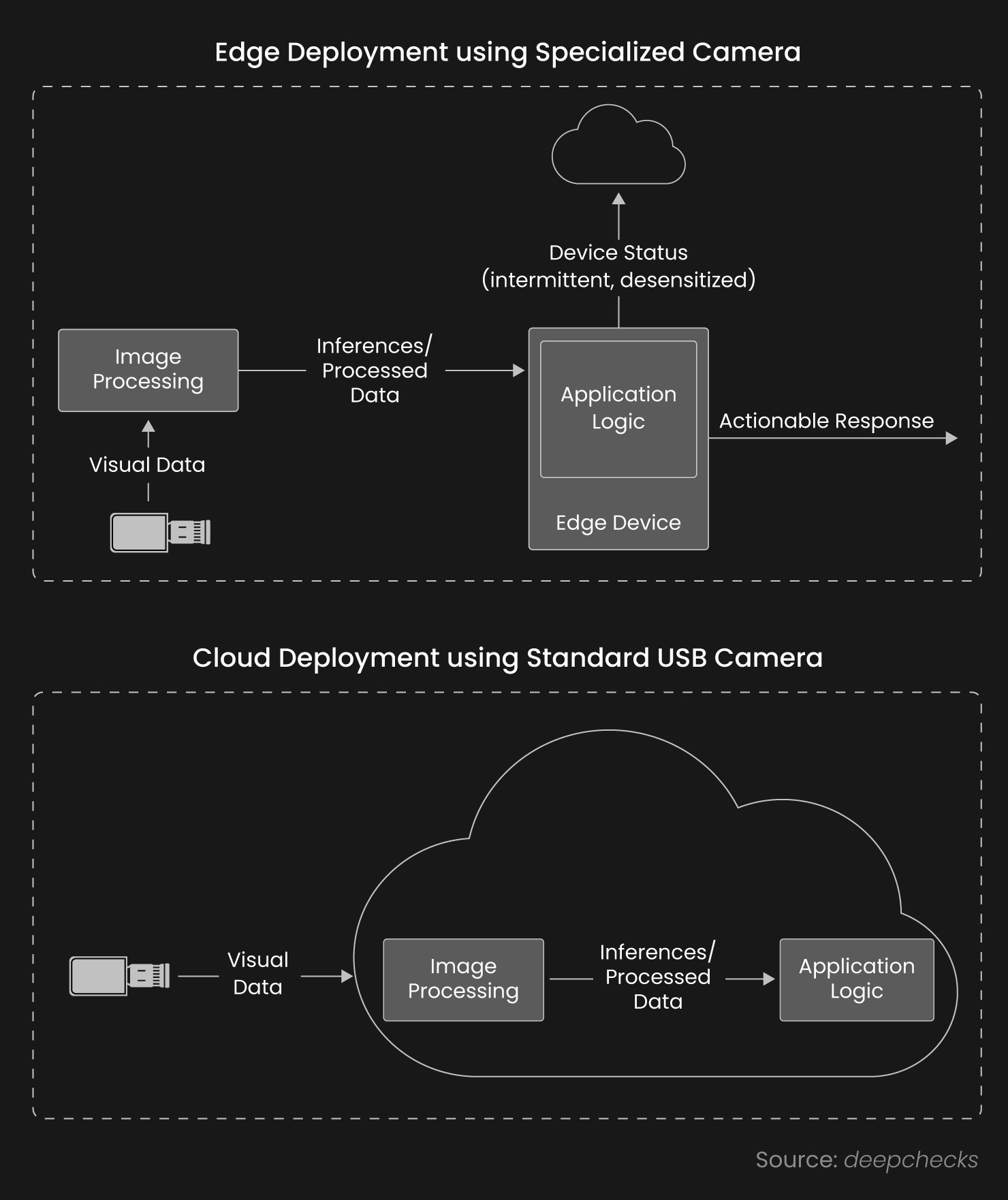
Fig: Cloud Vs Edge Deployment
As architecture matures, the focus has shifted toward consistent, maintainable deployment. Several developments in tooling and ecosystem design have made operationalizing modern vision models more systematic:
- Model Versioning and Dataset Governance: Tools like FiftyOne, Roboflow, and Weights & Biases now support vision-specific workflows.
- Prompt-based Inference APIs: Foundation models such as SAM and OpenCLIP are accessible through standardized endpoints, reducing integration complexity.
- Edge Deployment Toolchains: Frameworks like TensorRT, OpenVINO, and ONNX Runtime enable optimization and quantization for on-device inference without full model retraining.
The result is a shift from monolithic, experimental deployments to modular, scalable components that can be monitored, retrained, and versioned with enterprise-grade reliability.
Conclusion: A Foundation for Generalized Visual Intelligence
The frontier of Computer Vision is centered on isolated improvements in accuracy. The most valuable innovations now aim for adaptability, composability, and interoperability across systems. Models are expected to:
- Generalize across tasks with minimal fine-tuning
- Integrate with language and reasoning frameworks
- Operate in real-world environments, including edge and embedded systems
- Scale with minimal dependence on labeled data
This trajectory points toward Computer Vision systems that are not functionally capable but architecturally flexible, capable of becoming long-term infrastructure for perception across sectors.
In logistics, this translates to adaptive tracking and intelligent routing. In manufacturing, enabling fast-changing QA protocols without retraining. In retail, it powers context-aware product understanding. These are not incremental improvements but represent a foundational shift in how machine perception integrates into operational workflows.
For further insights into 2025 trends in Computer Vision models and how they help in Computer Vision solutions and use cases, Contact us.
Post Tags :
- Attention Mechanisms
- Computer Vision Models in 2025
- Edge Inference
- Label Efficiency
- Model Deployment
- Model Efficiency
- Model Scaling
- Multi-Task Learning
- Real-Time Detection
- Self-Supervised Training
- Task Generalization
- Transfer Learning
- Vision Architectures
- Vision Transformers
- Vision-Language Models
- Visual Understanding